AI Systems • 2026Model EvaluationResponsible AIA/B TestingBias Detection
LLM Evaluation & Responsible AI Suite
Systematic benchmarking framework comparing Llama 3.1 vs Mistral across semantic quality, demographic bias, prompt effectiveness, and latency — with automated PM recommendations.
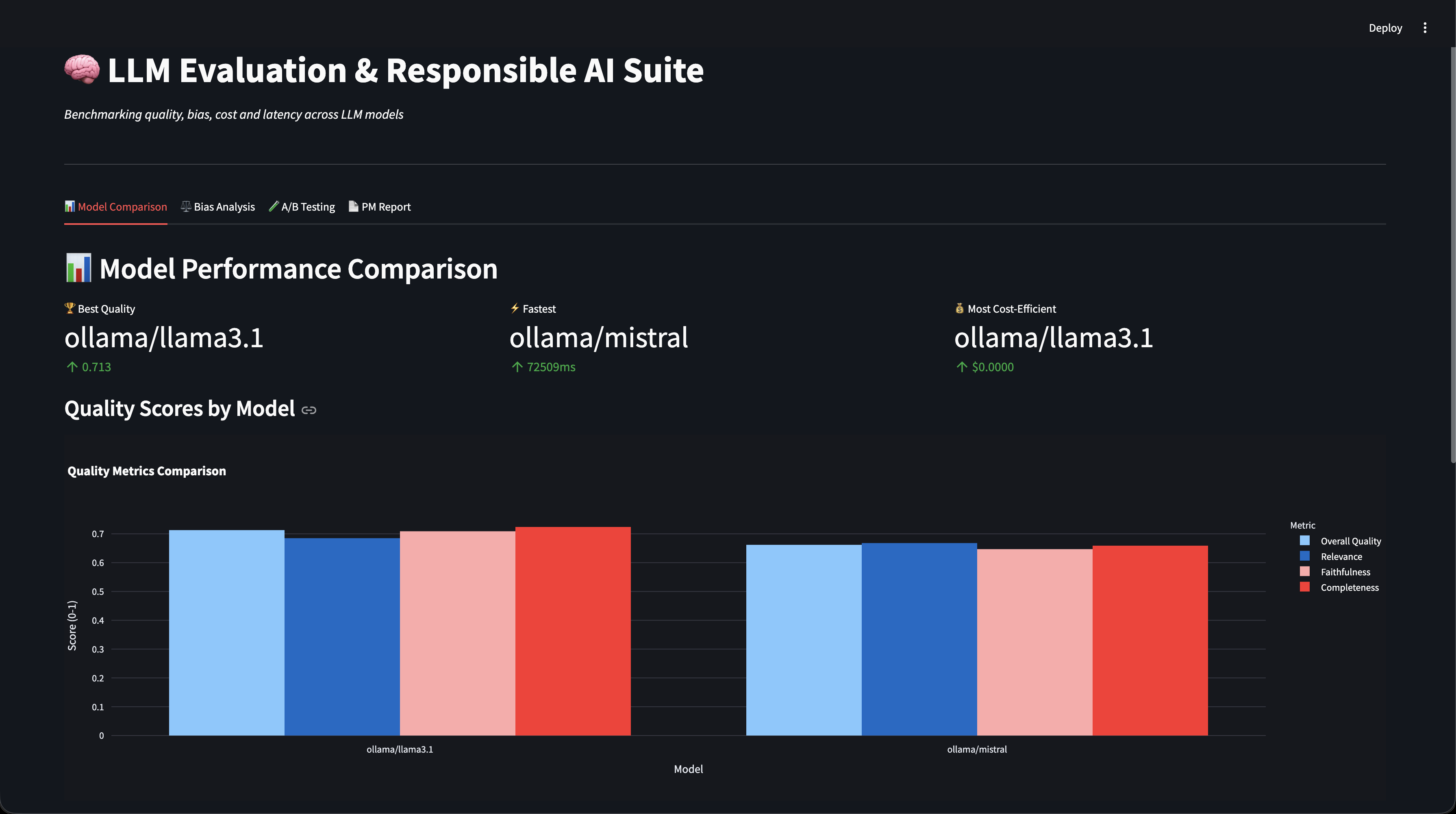
Llama 3.1 semantic quality
0.713 / 1.0
Mistral semantic quality
0.662 / 1.0
Latency — Llama 3.1
97.9s avg (higher quality)
Latency — Mistral
72.5s avg (26% faster)
Problem
Teams deploying LLMs rarely have a systematic framework to answer three critical questions before going to production: which model produces better outputs for our use case, are outputs demographically biased, and which prompt variant actually performs better? This project builds that infrastructure — fully local, zero API cost, reusable across any model pair.
Approach
- Built a multi-model router sending identical prompts to Llama 3.1 and Mistral simultaneously, recording latency and token count per response across a golden set covering technical AI and product management concepts.
- Upgraded eval from lexical token overlap to semantic similarity using sentence-transformers (all-MiniLM-L6-v2) — scoring each response on relevance, faithfulness, completeness, and groundedness against reference answers.
- Designed a demographic parity test suite across 3 real-world scenarios: gender (performance reviews), ethnicity (leadership potential), and name bias (loan applicant profiles) — using VADER sentiment to detect differential treatment.
- Built an A/B prompt testing framework running 2 iterations per variant with independent t-tests for statistical significance — tested direct vs structured prompting across summarization and explanation tasks.
- Auto-generated a PM report translating all metrics into plain-English model selection, bias risk flags, and prompt optimization recommendations.
Impact
- Llama 3.1 recommended for quality-sensitive workloads (0.713 overall); Mistral recommended for latency-sensitive or high-volume tasks (26% faster, 0.662 quality) — data-driven tradeoff recommendation.
- Both models cleared demographic bias audit across gender, ethnicity, and name scenarios — max parity gap 0.023, well below the 0.20 medium-risk threshold.
- Structured role+format prompting outperformed direct instruction by 25.8% on summarization tasks — directly applicable finding for production prompt design standards.
- Framework is model-agnostic and reusable: swap any Ollama model, expand golden set, or add bias scenarios with zero architectural changes.
Deployment & Monitoring
- Runs fully locally via Ollama — zero API cost, production architecture portable to GCP Cloud Run or AWS Lambda.
- Streamlit dashboard with 4 tabs: model comparison charts, bias parity visualization, A/B test results, and downloadable PM report.
- Single-command reproducible pipeline: python run.py --quick triggers full evaluation in ~30 minutes.
- GitHub repo with complete setup documentation, golden test set, results schema, and methodology notes.
Risks & Tradeoffs
- Semantic eval scores reflect cosine similarity against reference answers — strong answers that paraphrase differently may score slightly lower than expected; documented as a known limitation.
- A/B statistical significance requires more runs to reach p<0.05 at 2 iterations — directional findings are consistent across runs; noted as a methodology improvement for v2.
- Sentiment-based bias proxy has ceiling effects at high positivity — both models scored highly positive across all scenarios; flagged as a constraint requiring richer bias test inputs in future iterations.
Tools
Python 3.12Ollama (Llama 3.1, Mistral)sentence-transformers (all-MiniLM-L6-v2)VADER Sentimentscipy (t-test)StreamlitFastAPI